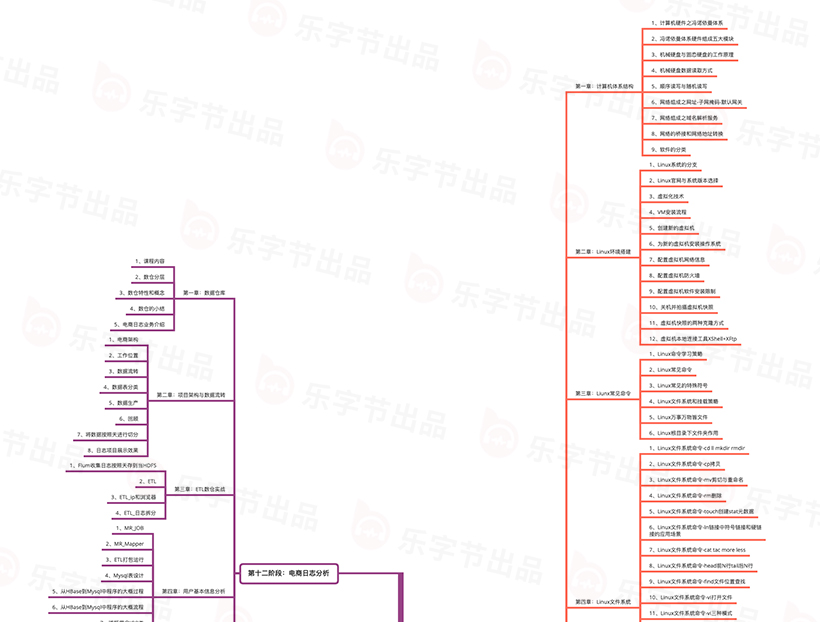
第二章:Linux环境搭建
本章主要讲解: 本章开始讲解Linux的系统分支,安装Linux的产品Centos,为后续的学习准备好环境。并且结合阿里云腾讯云等系统讲解虚拟化服务,将Linux环境安装运行到VM上。
共 11 节
无需基础,循序渐进,一学封神【购买说明】此商品为虚拟商品,一经购买,概不退款。
难度: 初级 时长:130小时 学习人数:3768人 随到随学答疑辅导配套教辅
本章主要讲解: 计算机系统结构是计算机的机器语言程序员或编译程序编写者所看到的外特性。这节课从基础开始讲起让大家对后期程序运行过程有一个较底层的了解。
共 11 节
本章主要讲解: 本章开始讲解Linux的系统分支,安装Linux的产品Centos,为后续的学习准备好环境。并且结合阿里云腾讯云等系统讲解虚拟化服务,将Linux环境安装运行到VM上。
共 11 节
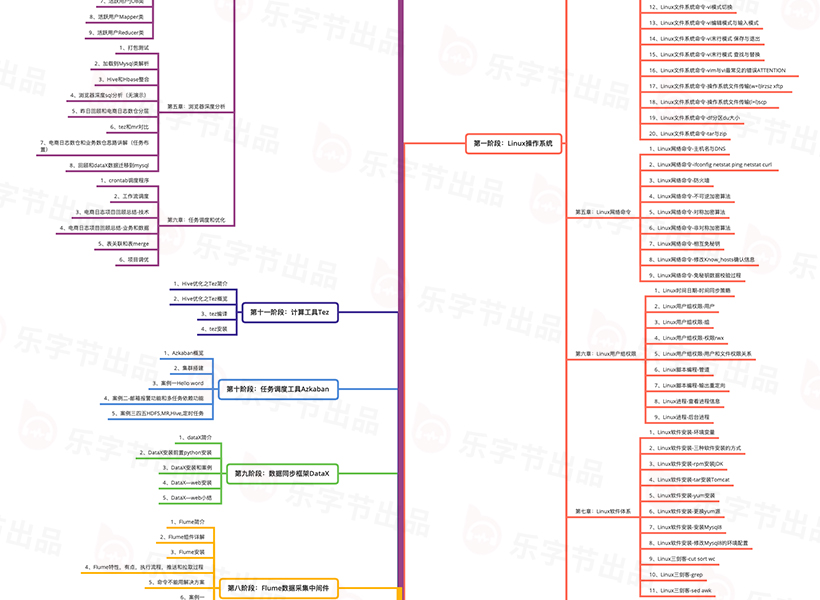
本章主要讲解: 本章主要讲述Linux的命令使用方式,告诉同学们命令大概的执行过程和命令的书写格式。
共 4 节
本章主要讲解: 本章课开始讲解Linux的文件系统,也是Linux最主要的部分,文件的创建删除剪切复制日常操作都在里面体现。
共 18 节
本章主要讲解: 本章主要讲解Linux的网络,多个电脑通过网络系统进行数据的传递,最主要的还是三种加密算法和主机间的相互免秘钥的访问。
共 11 节
本章主要讲解: 本章主要讲述用户组权限,什么用户可以操作什么类型的文件,应对多用户模式下权限的执行情况。
共 8 节
本章主要讲解: 本章主要讲述Linux环境下软件的安装方式,并以Java和Tomcat和Mysql为主进行案例练习。
共 6 节
三剑客
共 4 节
本章主要讲解: 本章主要讲述Linux常见的脚本执行方式,相当于Java的基础语法,由浅入深逐渐掌握Liunx语法。
共 3 节
本章主要讲解: 本章主要在上一章的基础上进行扩容,对执行逻辑语句、函数和计算机运行原理进行进阶型学习,以后工作中即使遇到在复杂的问题也能轻松解决。
共 7 节
本章内容是对Linux知识的扩充学习,基于Linux之上搭建Nginx环境,了解负载均衡和反向代理的意义,而且可以为以后的项目中也会用到Nginx做日志收集服务器
共 14 节
本章主要讲述数据一致性的概念,为后续的Zookeeper提供理论的基础,而且可以推广到后续的集群环境
共 11 节
搭建Zookeeper环境,进行常见命令和架构的学习,主要内容是命令和监听机制,为以后的Hadoop环境搭建提供支撑
共 9 节
首先简历Hadoop的大数据思维,但是好多同学的基础偏弱,补充大数据学员常识性知识10大排序算法,了解算法的复杂度,为后续设计大数据算法也提供算法效率判定提供理论基础
共 10 节
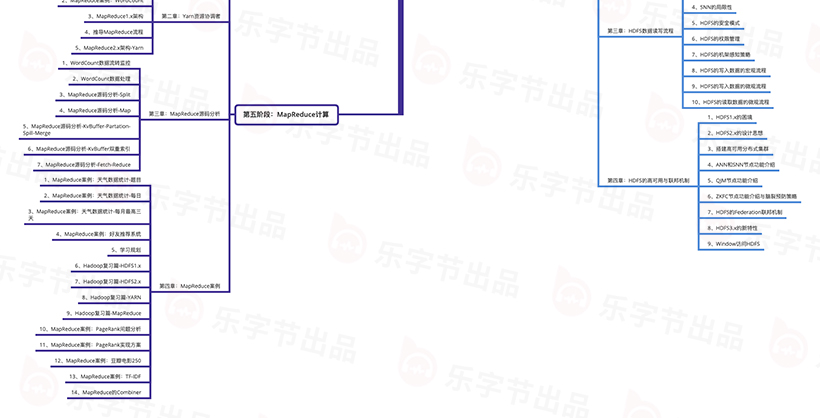
本章内容为大数据学习底层Block组成和架构,如何从大数据的思维去存放数据,只有数据存放的好才能进行高效的计算
共 13 节
本章主要内容为大数据存储策略,如果用更高效的速度去读取数据,如何使用更安全的方式去读取数据都是大数据开发人员必须要要掌握的技能
共 12 节
本章讲解大数据2.x和3.x的技术升级,突出的就是高可用与联邦机制,通过这个地方的学习也是对数据一致性学习的补充
共 22 节
本章内容首先捋顺MapReduce计算的流程,先掌握理论后实践。从数据最开始跟踪整个数据流,顺藤摸瓜解决所有难题
共 10 节
讲解Hadoop2.x新特性资源协调框架,了解资源协调框架的作用和实现方式,并且将Yarn配置到集群中监控任务的执行
共 6 节
本章比较重要也比较难,因为开始对源码进行分析,这需要大家提前掌握好前面的理论知识,前面所有的流程都会在源码中一一呈现,为将来提升自己与面试加分
共 11 节
Hadoop的重要性在大数据的学习中是无用质疑的,我们花费一章的时间重新复习Hadoop的技术架构,发现第一次学习中遗忘的知识点,从新的角度发掘大数据的魅力,并且重新用新案例验证我们的学习成果
共 19 节
比对MapReduce和Hive优缺点,整理Hive的系统架构,搭建Hive运行环境,为后续的学习准备环境
共 6 节
DDL语句
共 17 节
学习大数据中第一种分布式非关系型数据库,体验亿级数据的秒查询,搭建HBase环境,讲解Hbase架构,练习基础型的命令,以实践掌握知识
共 10 节
本章开始Hbase技巧性的学习,Hbase数据访问方式
共 7 节
HBase系统架构
共 10 节
HBase设计案例
共 7 节
讲解Flume新版本的相关信息,比如Flume如何实现高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统的?Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力
共 13 节
本章讲解的Datax主要功能是数据迁移,DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。
共 7 节
本章讲解的Azkaban是在LinkedIn(领英)上创建的用于运行Hadoop作业的批处理工作流作业调度程序。Azkaban通过工作依赖性解决订购问题,并提供易于使用的Web用户界面来维护和跟踪您的工作流程。
共 6 节
本章讲解的Tez是Apache最新的支持DAG作业的开源计算框架,它可以将多个有依赖的作业转换为一个作业从而大幅提升DAG作业的性能。Tez并不直接面向最终用户——事实上它允许开发者为最终用户构建性能更快、扩展性更好的应用程序。Hadoop传统上是一个大量数据批处理平台。
共 2 节
系统架构和数据处理分析
共 5 节
电商日志分析项目的架构搭建,数据流转、表分类以及按天划分,在展示项目。
共 9 节
MapReduce计算活跃用户
共 5 节
ETL/Analysis代码梳理
共 6 节
新增用户业务分析和代码实现
共 2 节

 沪公网安备 31011502015406号
沪公网安备 31011502015406号




